
大语言模型在古生物学教学中的初步探索
在人工智能技术日新月异的今天,科学研究正面临前所未有的范式变革。大语言模型不再仅仅是辅助文献阅读的工具,而是正在成为推动各学科深度发展的关键力量。在这场技术革命中,古生物学作为一门专业性强、知识体系庞杂且相对小众的学科,可能也将迎来数字化转型的又一重要契机。
近期,中国科学院南京地质古生物研究所的黄冰研究员在古生物学报发表了《大语言模型在古生物学中的应用初探 ——以基于RAG的知识问答系统为例》一文,首次系统性探索了开源大语言模型在古生物学专业知识获取中的应用价值。这项研究为该学科的教学与研究提供了新的可能思路。
2024年国内外涌现了诸多商业大语言模型,虽然功能强大,但使用门槛高且数据安全性难以保障等因素限制了其在特定学科研究中的应用。针对这一情况,黄冰研究员采用当时生态最为完整的开源大语言模型Llama 系列中的Llama 3.1:8b的本地部署方案,以腕足动物知识问答系统为实验对象,构建了基于基础检索增强生成(Naive RAG)的知识平台。该系统通过问答互动可以有效促进学生对腕足动物专业知识的理解与掌握(表1),为教学过程注入新的活力。

当前该系统主要以教学意义为主,在应用层面仍存在优化空间。作者前瞻性地提出了基于图检索增强生成(Graph RAG)和代理检索增强生成(Agent RAG)的改进方案,为未来发展奠定了理论基础。值得期待的是,基于知识图谱的腕足动物Graph RAG系统(图1)即将进入开发阶段(将采用DeepSeek-R1-Distill-Qwen2.5-7b蒸馏模型作为基座模型),有望在不久的将来为腕足动物研究提供更为有力的智能支持,并可能为古生物学其他门类研究提供有益借鉴。
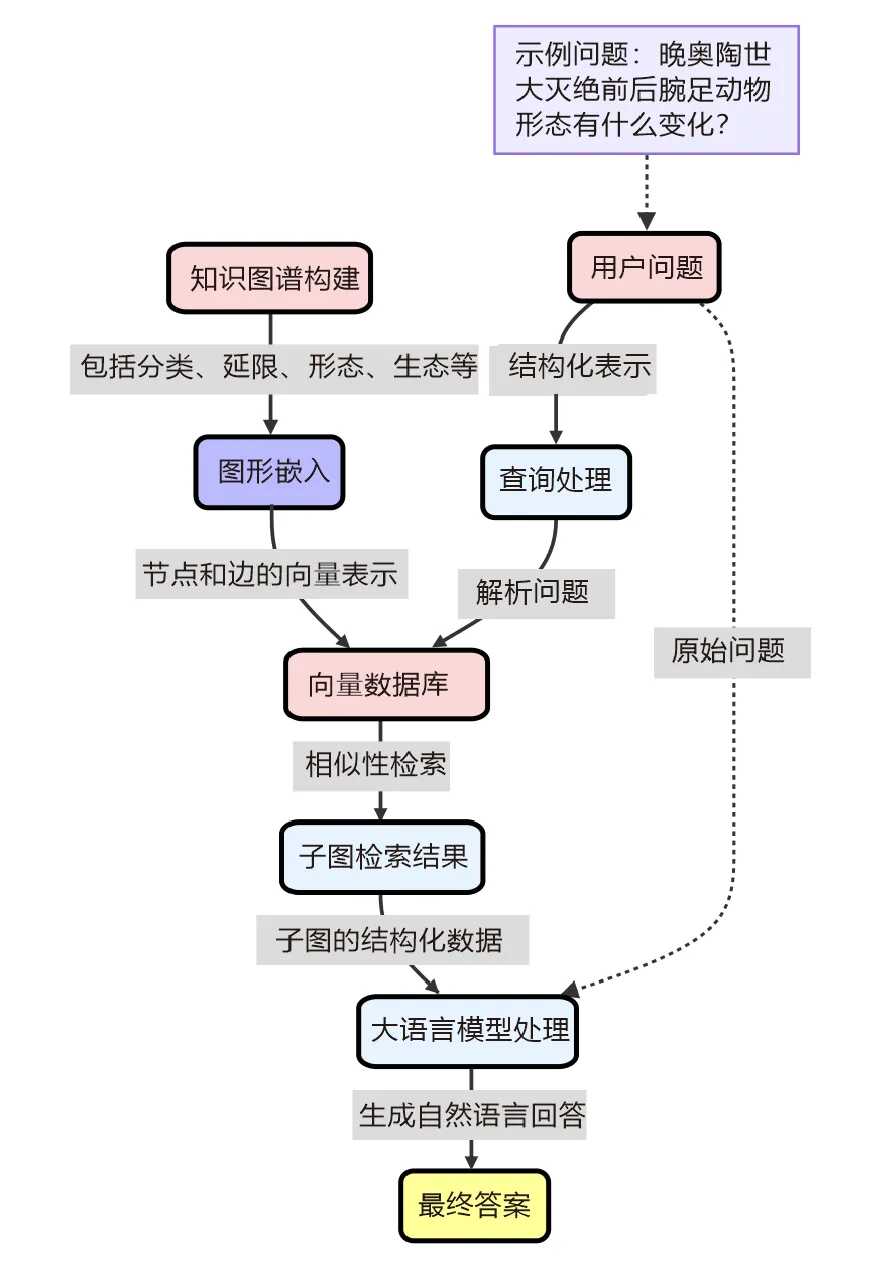
图1 腕足动物问答系统的GranphRAG解决方案流程图
可以预见,在未来人工智能引发的科研新范式下,人类科学家的角色将转向更具战略性的工作,即发现和定义科学问题、把控研究方向、通过提示工程协调多智能体系统的运作。这种转变不是对人类科研能力的替代,而是通过AI增强实现科研效能的整体提升,未来的科研活动将更可能是一个人机协同的有机整体。面向科学研究的人工智能系统已开始在各个学科快速部署,正如谷歌最近的发文所述,面向科学研究人工智能的黄金时代已经来临。古生物学作为一个长尾知识领域代表,是否需要并可以把握这个机遇,值得每一位古生物学者的关注与思考。
编辑:诸鹏飞
审核:盛捷